
My friend passed me a Intel RealSense cam and ask me to explore its power and ability. Initially I am thinking of using for 3D scanning or facial recognition projects . But I think a ‘people counting and social distancing automation robot’ is more practical 🤙. So let’s begin to code and build. 🤖
Below 3 pics shows the Z axis (distance) measurement capability of the D415. You have to zoom in to see the reading(distant reading pointed by the arrow).
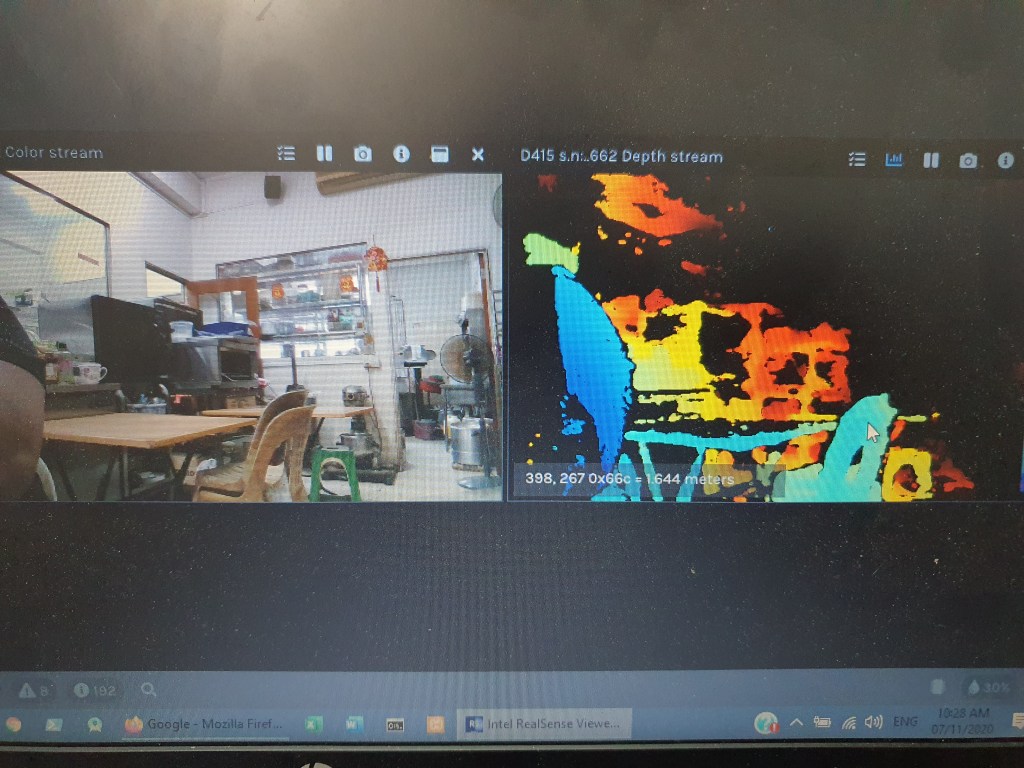
chair distant at 1.644m 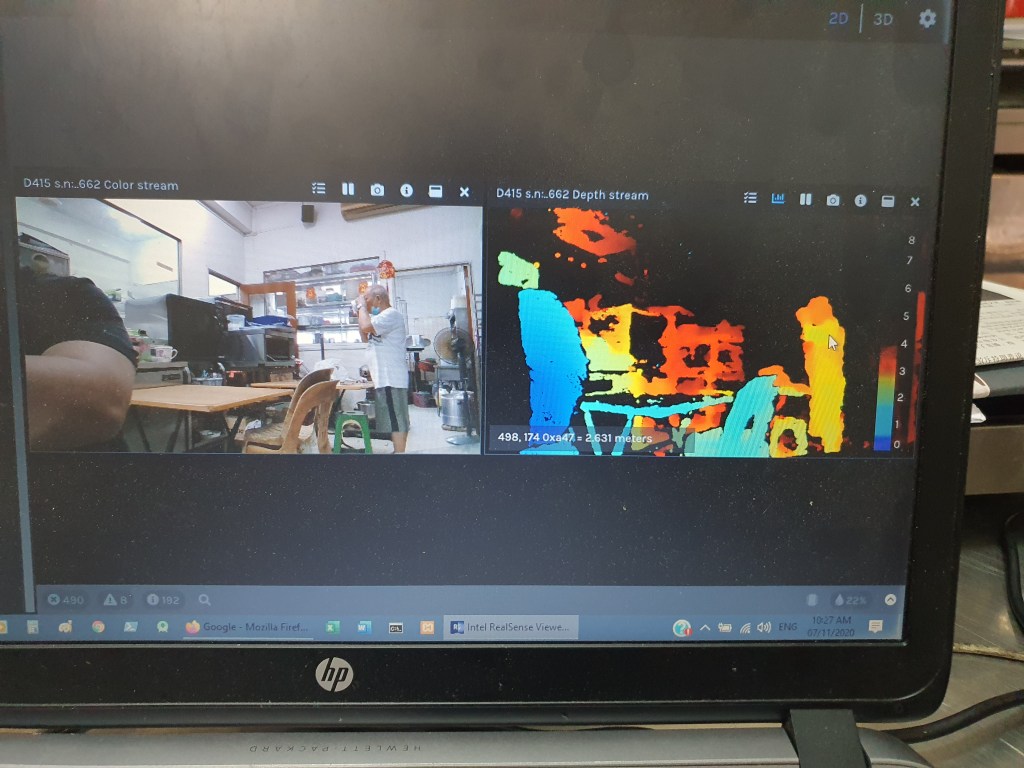
standing man distant at2.631m. 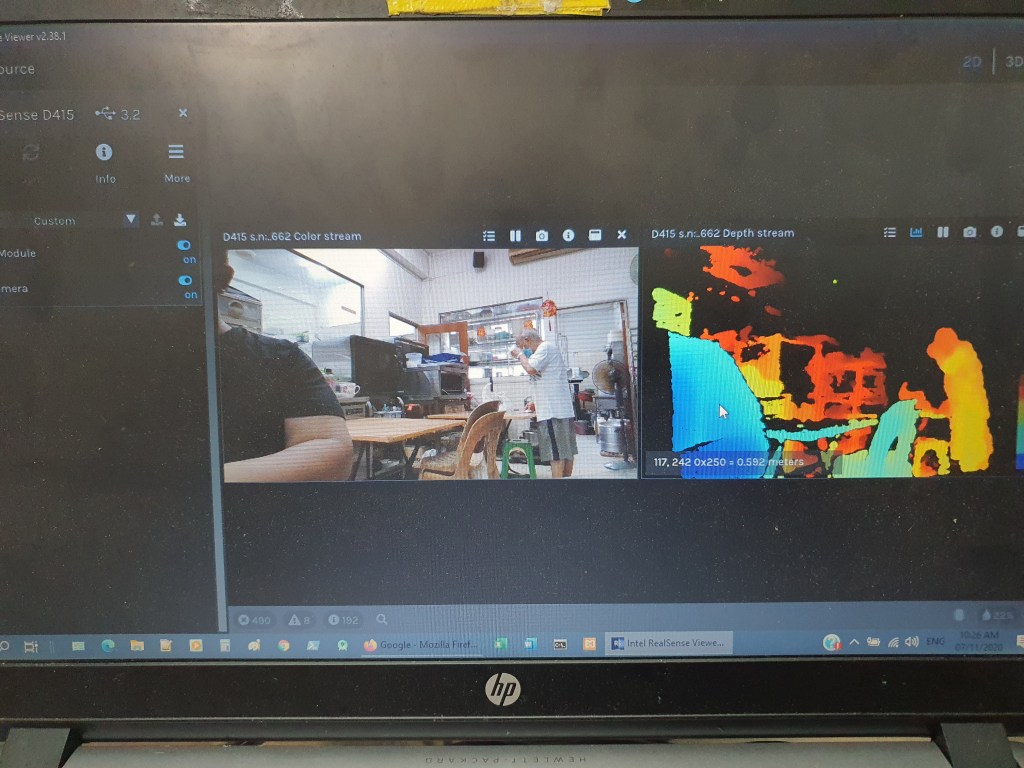
my left arm distant at 0.592m
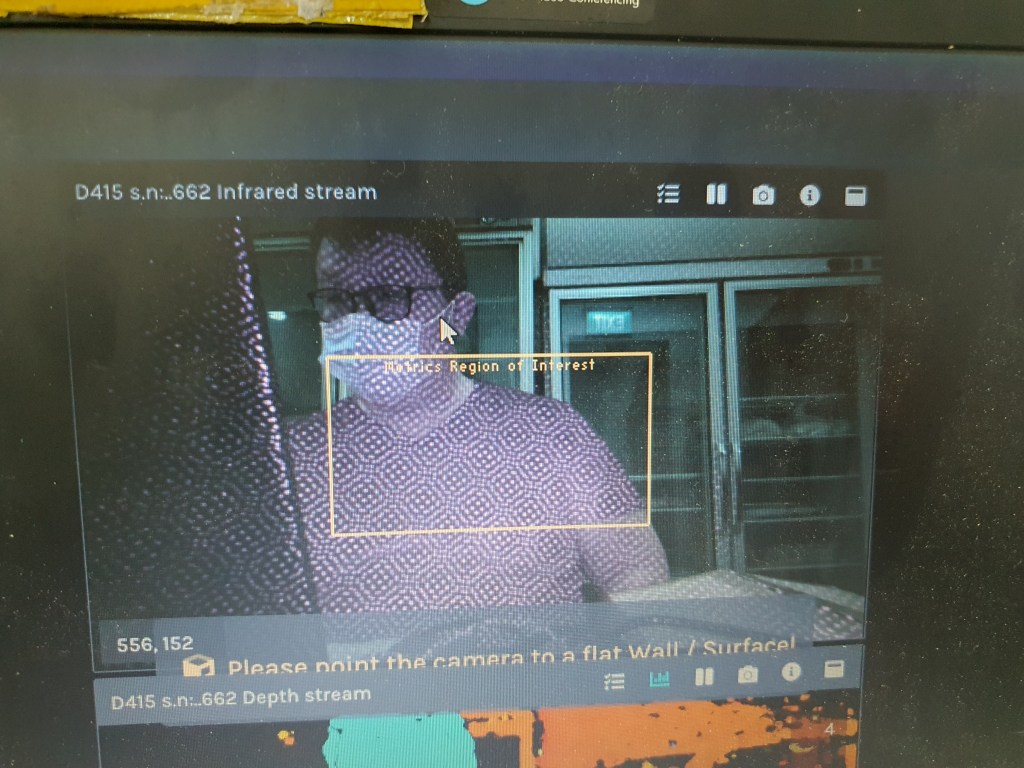
Using the Intel sdk Depth Quality Tool, the Depth Stream window gives us distant and the IR stream gives us the pixel pointed by the mouse. Both provide ROI window which can be controlled at the side menu bar.
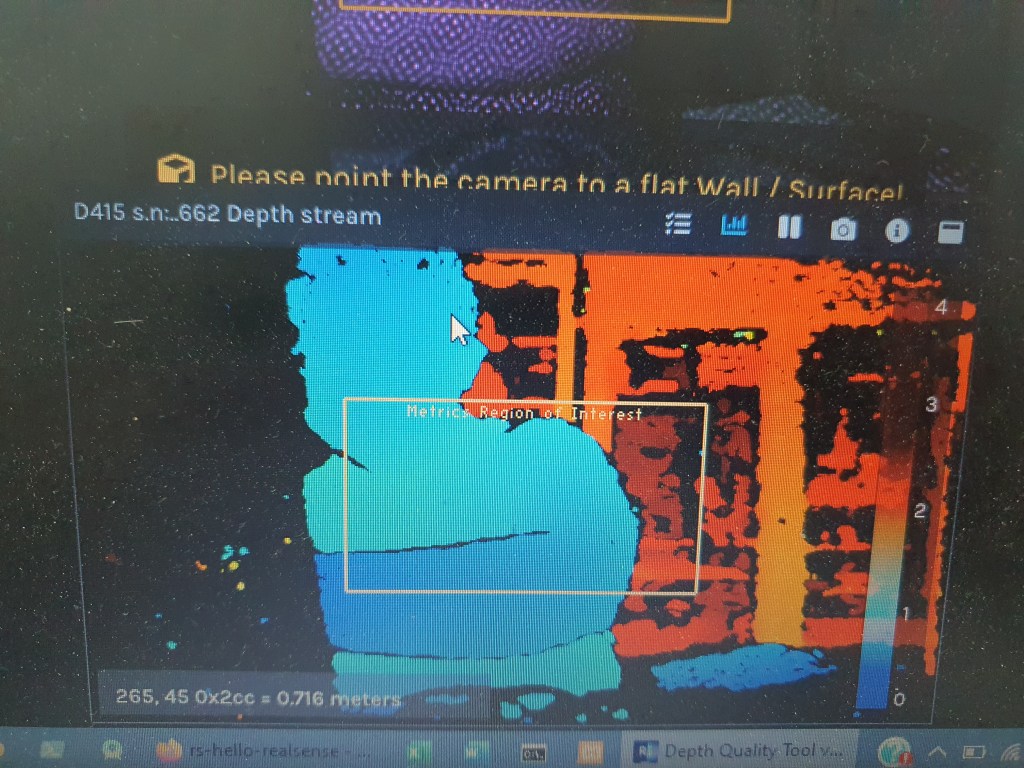

To interface D415 with Python Opencv, certain libraries have to be downloaded:
- Opencv
- Pyrealsense2
Download CMake.
Ok, let’s start to build the system for counting people.
Using Intel D415 depth camera to build a people counter
In this post, we will use Python OpenCV deep learning module call DNN(Deep Neural Networks). DNN is not an end to end deep learning framework, which means we can’t train the network as there is no back propagation hence no learning takes place.
The input is fed into a pre-trained model which produces the results. This is refer to as inference and only forward pass takes place.
The DNN process:
Following is the Python code for using OpenCV DNN to detect objects in a streamed in video.
import cv2
import numpy as np
cam = cv2.VideoCapture(2)
if cam.isOpened()==False:
print("No video Stream")
#cam.set(3,224)
#cam.set(4,224)
cam.set(cv2.CAP_PROP_FRAME_WIDTH, 1920)
cam.set(cv2.CAP_PROP_FRAME_HEIGHT,1080)
all_rows = open(r'C:\Users\Ls\Documents\ACCS\blog post\synset_words.txt').read().strip().split("\n")
classes = [r[r.find(' ')+1:] for r in all_rows]
net = cv2.dnn.readNetFromCaffe(r'C:\Users\Ls\Documents\ACCS\blog post\bvlc_googlenet.prototxt',r'C:\Users\Ls\Documents\ACCS\blog post\bvlc_googlenet.caffemodel')
while (True):
ret, frame = cam.read() # capture frame from video
blob = cv2.dnn.blobFromImage(frame,1,(224,224))
net.setInput(blob)
outp = net.forward()
r=1
for i in np.argsort(outp[0])[::-1][:5]:
txt = ' "%s" probability "%.3f" ' % (classes[i], outp[0][i]*100)
cv2.putText(frame,txt, (0, 25 + 40*r), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,0,0),2)
r+=1
#imgGray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('Frame', frame)
# loop will be broken when 'q' is pressed on the keyboard
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cv2.waitKey(200)
cam.release()
cv2.destroyWindow('Frame')
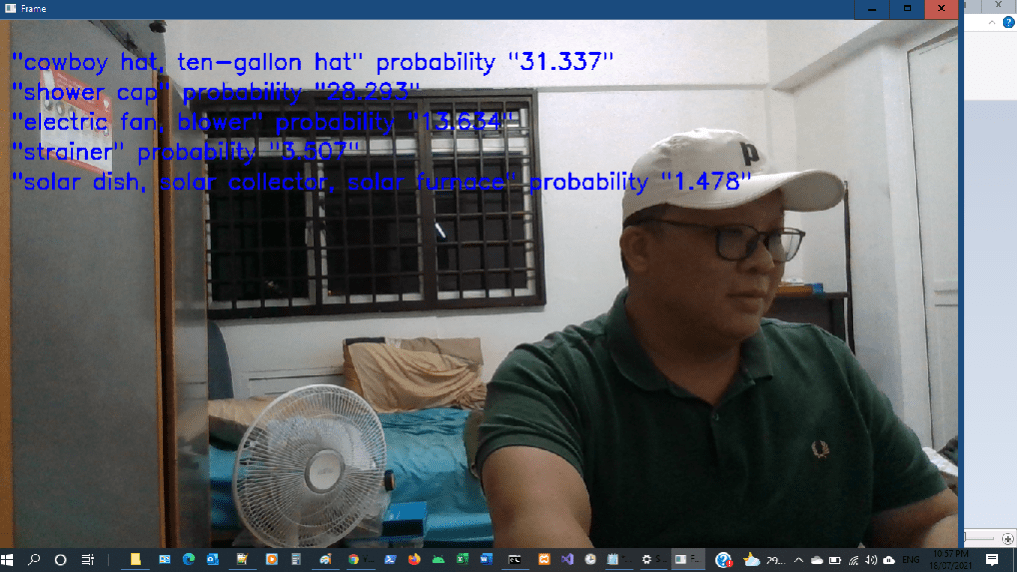
Below is the video screenshot of the objects identified and their probabilty.
- cowboy hat 31.337% – not really correct, I’m wearing a cap
- Shower cap 28.293% – Cap is correct but not for shower
- electric fan – 13.634% – Correct
- Strainer 3.507% and solar dish 1.478% – I think the window grill does look like a big strainer 😉 and the grill with black colour window glass does look like a solar panel 😀
Now we will use YOLO (you only look once) version 3 together with Caffe and Darknet deep learning framework :
The official website for Yolo: pjreddie.com/darknet/yolo/, where you can learn and better understand Yolo.
The Python code can be downloaded from Github.
# Usage:
# python yolo.py --video=<path to video file>
# python yolo.py --image=<path to image file>
import numpy as np
import cv2
import argparse
import sys
import numpy as np
import os.path
# Initialize the parameters
confThreshold = 0.5 #Confidence threshold
nmsThreshold = 0.4 #Non-maximum suppression threshold
parser = argparse.ArgumentParser(description='Object Detection using YOLO in OPENCV')
parser.add_argument('--image', help='Path to image file.')
parser.add_argument('--video', help='Path to video file.')
args = parser.parse_args()
# Load names of classes from coco
classes = open(r"C:\Users\Linawati\Documents\ACCS\blog post\coco.names").read().strip().split('\n')
net = cv2.dnn.readNetFromDarknet(r"C:\Users\Linawati\Documents\ACCS\blog post\yolov3.cfg", r"C:\Users\Linawati\Documents\ACCS\blog post\yolov3.weights")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
# Get the names of the output layers
def getOutputsNames(net):
# Get the names of all the layers in the network
layersNames = net.getLayerNames()
# Get the names of the output layers, i.e. the layers with unconnected outputs
return [layersNames[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# Draw the predicted bounding box
def drawPred(classId, conf, left, top, right, bottom):
# Draw a bounding box.
cv2.rectangle(frame, (left, top), (right, bottom), (255, 178, 50), 3)
label = '%.2f' % conf
# Get the label for the class name and its confidence
if classes:
assert(classId < len(classes))
label = '%s:%s' % (classes[classId], label)
#Display the label at the top of the bounding box
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
cv2.rectangle(frame, (left, top - round(1.5*labelSize[1])), (left + round(1.5*labelSize[0]), top + baseLine), (255, 255, 255), cv2.FILLED)
cv2.putText(frame, label, (left, top), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0,0,0), 1)
# Remove the bounding boxes with low confidence using non-maxima suppression
def postprocess(frame, outp):
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
# Scan through all the bounding boxes output from the network and keep only the
# ones with high confidence scores. Assign the box's class label as the class with the highest score.
classIds = []
confidences = []
boxes = []
for out in outp:
for detection in out:
scores = detection[5:]
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold:
center_x = int(detection[0] * frameWidth)
center_y = int(detection[1] * frameHeight)
width = int(detection[2] * frameWidth)
height = int(detection[3] * frameHeight)
left = int(center_x - width / 2)
top = int(center_y - height / 2)
classIds.append(classId)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
# Perform non maximum suppression to eliminate redundant overlapping boxes with
# lower confidences.
indices = cv2.dnn.NMSBoxes(boxes, confidences, confThreshold, nmsThreshold)
for i in indices:
i = i[0]
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
drawPred(classIds[i], confidences[i], left, top, left + width, top + height)
outputFile = "YOLOv3_output.avi"
if (args.image):
# Open the image file
if not os.path.isfile(args.image):
print("Input image file ", args.image, " doesn't exist")
sys.exit(1)
cap = cv2.VideoCapture(args.image)
outputFile = args.image[:-4]+'_YOLOv3_output.jpg'
elif (args.video):
# Open the video file
if not os.path.isfile(args.video):
print("Input video file ", args.video, " doesn't exist")
sys.exit(1)
cap = cv2.VideoCapture(args.video)
outputFile = args.video[:-4]+'_YOLOv3_output.avi'
else:
# Webcam input
cap = cv2.VideoCapture(0)
# Get the video writer initialized to save the output video
if (not args.image):
vid_writer = cv2.VideoWriter(outputFile, cv2.VideoWriter_fourcc('M','J','P','G'), 30, (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))))
while cv2.waitKey(1) < 0:
hasFrame, frame = cap.read()
# Stop if end of video
if not hasFrame:
print("File with YOLOv3 output is here : ", outputFile)
cv2.waitKey(5000)
cap.release()
break
# Create a 4D blob from a frame.
blob = cv2.dnn.blobFromImage(frame, 1/255, (416,416), [0,0,0], 1, crop=False)
# Sets the input to the network
net.setInput(blob)
# Runs the forward pass to get output of the output layers
outp = net.forward(getOutputsNames(net))
# Remove the bounding boxes with low confidence
postprocess(frame, outp)
# Write the frame with the detection boxes
if (args.image):
cv2.imwrite(outputFile, frame.astype(np.uint8))
else:
vid_writer.write(frame.astype(np.uint8))
cv2.imshow('Image', frame)
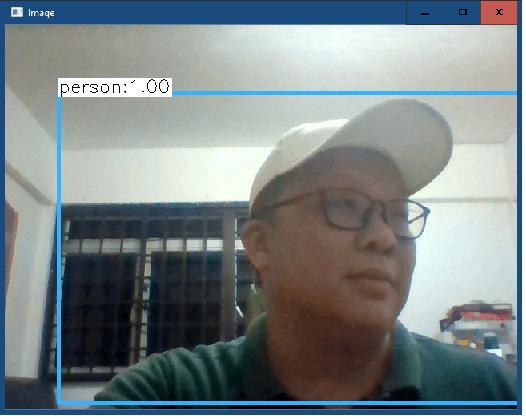
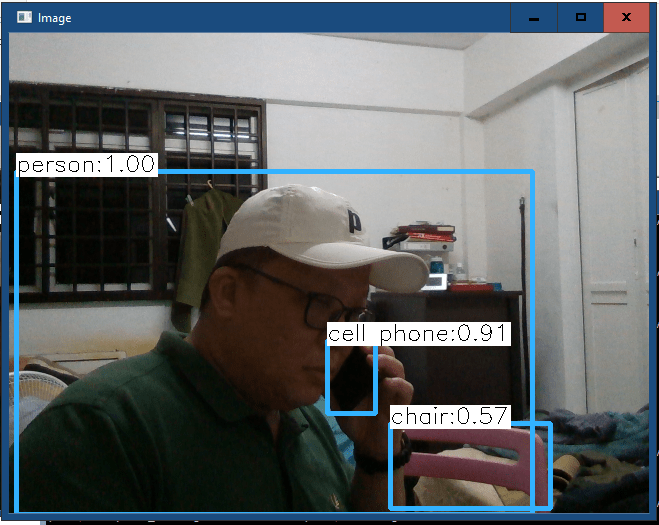
I added another condition in the If/elif/else statement(line 108 to 110) as I am using a live video steam as the input. The 1st below pic is using the webcam (with cap = cv2.VideoCapture(0)) and the 2nd below pic is using the Intel D415 camera.
I change the argument for the VideoCapture to 2 (cap = cv2.VideoCapture(2)) which means the input stream is from a USB camera (Intel D415).

Ok, so the finally step is to count the number of persons and tabulate into somewhere like Excel, csv sheet or even to the cloud.
to be continue……. very soon
