
Perceptron(Artificial Neuron) – Weighted sum of inputs(SUM(Wi*xi)) + bias(b) , feed into an activation function. Output from fn will determine if neuron is fire or not. This is a binary classifier. The network need to determine the value of W and b and to quantify the error.
Gradient Descent
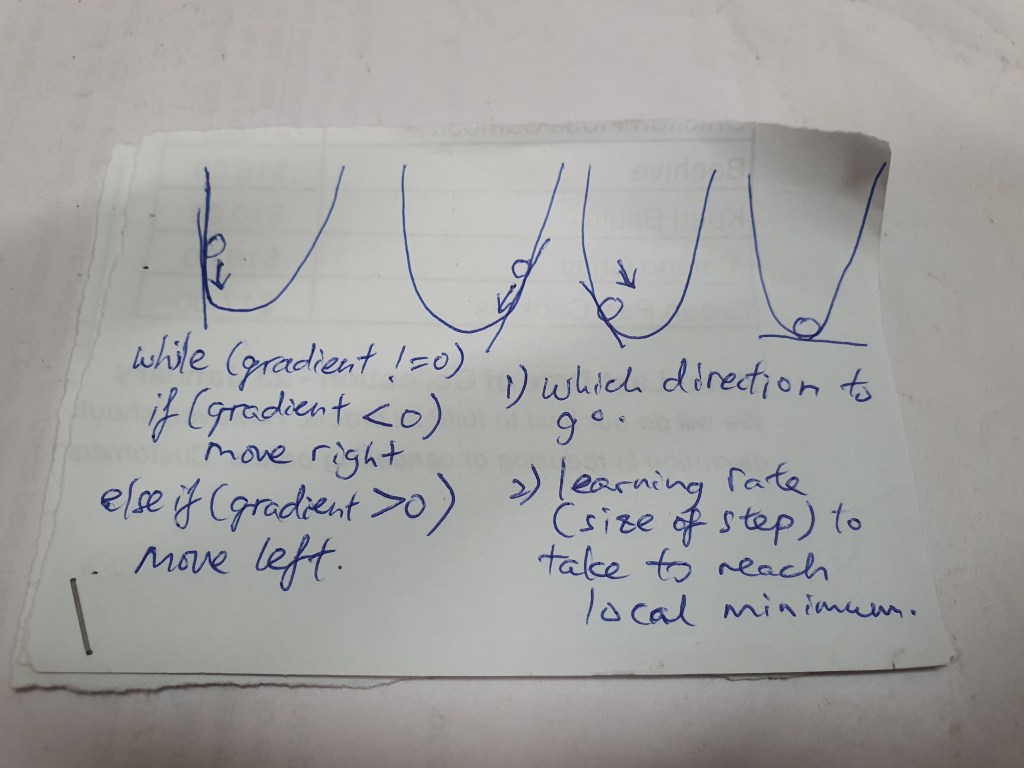
Difference between input and output are call loss and to improve model prediction capability, we want to minimise loss. Gradient Descent is an optimizing algorithm, will iterate different combinations of W and b to find the combi to minimise the loss.
The XOR (Exclusive OR) problem
Linear function some times cannot separate some classes of data. Sigmoid and Tanh(hyperbolic) functions have vanishing gradient issues hence affect performance. They will saturate, which means, large inputs will tend to become 1 and small values jump towards -1(Tanh) and 0(sigmoid). They are only good and sensitive for inputs near their mean.
ReLU (Rectified Linear Unit) function is the most popular one to solve the XOR problem. It is a piecewise linear non-saturating activation function make famous by AlexNet’s creator.
Hyperparameters
Hyperparameters are parameters that are set before the learning process (training). Such as: what activation function to use, how many neurons in each layer, learning rate, how many hidden layers.
Visualization tool for ML
this site provide cool visualization for you models : playground.tensorflow.org
